Spying on the Office Step 1 - Slack Wiretap
A first look at the hijinks which ensue as we start using technology to spy on the office. Co-authored by Nate Paulus and Paul Michelotti.
A first look at the hijinks which ensue as we start using technology to spy on the office. Co-authored by Nate Paulus and Paul Michelotti.
Buzzing technologies like IoT, Big Data, Streaming Data, Real Time Insights, and Personal Assistants really boil down to one thing … spying. And what better place to start spying than your own back yard, or in our case, our company offices? To that end, this post is the first in an ongoing series we’ve uncreatively titled “Spying on the Office”. Follow along as we engage in a number of projects aimed at excusing the usage of some interesting toys usually associated with these buzzing technologies.
Our first project is going to be the warehousing and processing of messages sent in the office Slack team. Some high-level goals for the project include:
Eventually we also want to include real-time analytics and insight in addition to scheduled bulk processing. For iteration one, we are sticking to the latter, but we want our system design to be informed by our long-term goals.
The paid Slack account does afford some capability to retrieve a message history; however, this appears to be a largely manual effort. Further, the processing of messages in real time is predicated upon our ability to get those messages in real time. This led us to the usage of the Slack Outgoing Webhook1 mechanism. As a custom integration, you can provide Slack with a URL to post to each time a message meeting specific criteria is received. We want to capture all public messages, so our configuration is channel-based such that each message sent to provisioned channels is sent to a URL we have specified.
token=XXXXXXXXXXXXXXXXXX
team_id=T0001
team_domain=example
channel_id=C2147483705
channel_name=test
timestamp=1355517523.000005
user_id=U2147483697
user_name=Steve
text=googlebot: What is the air-speed velocity of an unladen swallow?
trigger_word=googlebot:
Figure 1 — Sanitized payload from Slack. The API Gateway receives input as query parameters which we transform to JSON via Gateway template mapping
Of course, this means we need something at the other end of that URL, ready to consume potentially high volumes of data. The mix we landed on, pictured in Figure 2, involves the orchestration of a handful of AWS technologies. The goal of the architecture was to allow for theoretically infinite scalability of ingestion with minimized cost and little to no engineer intervention.
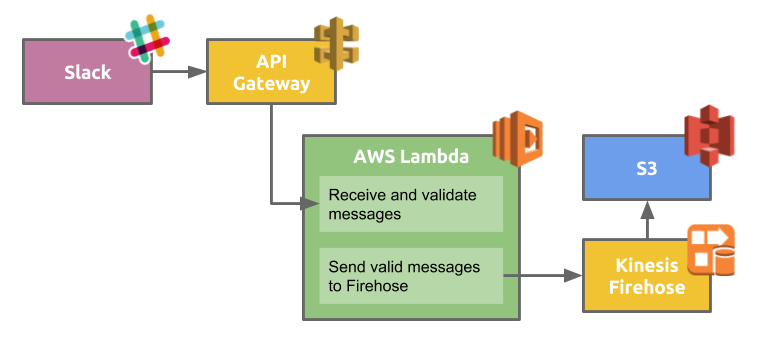
AWS’s API Gateway exposes our ingestion point for Slack messages. It is a fully managed and metered service, meaning that it will scale based on need and will cost based on use without engineer intervention. Additionally, the API Gateway provides a way to transform the incoming HTTP traffic from Slack into any desired format for backend processing. In the case of the Slack Message Processor, the transformation is from HTTP query parameters to the JSON format expected by the AWS Lambda to which our endpoint is associated.
The Lambda backing our endpoint in the API Gateway is quite simple. Its responsibilities are to verify, based on the token sent, that the event in fact came from Slack, and send verified events to the next step in the system, Kinesis Firehose. Lambdas are ideal for handling HTTP events like this, because instances of them can be spun up quickly as throughput need increases and are short-lived so they are not incurring cost when traffic decreases. When new instances are created and decommissioned is based on need as managed by the AWS infrastructure and does not require ongoing monitoring from an engineer.
Lambdas pair perfectly with the API Gateway, as both will scale automatically. Theoretically, this allows for limitless real-time ingestion of messages from Slack with virtually no maintenance effort from an engineer.
Firehose is AWS’s implementation of some common Kinesis use cases. The particular flavor we are interested in is Kinesis to S3. The beauty of Firehose over using Kinesis vanilla is that it is fully managed. With vanilla Kinesis you need to monitor throughput and shard or merge your stream as throughput needs increase and decrease, or start with far more shards than you imagine ever needing and thus over pay for the service. Firehose deals with this for you, meaning the stream scales without intervention.
The S3 flavor takes input events and dumps them into S3 in a certain bucket structure as the events reach the end of the stream.
Firehose collects data up to a configurable data size or time threshold then persists it to S3. Within S3, Firehose uses a specific bucket structure and filename convention to organize the collected data for easy retrieval. The bucket structure Firehose creates is based on UTC. For example, if Firehose collected data at 10am on November 18, 2016, then it would create this bucket structure:
/YEAR/MONTH/DAY/HOUR/ -> /2016/11/18/10/
In a particular hour bucket, Firehose will generate S3 objects that are named in the following format4:
DeliveryStreamName-DeliveryStreamVersion-YYYY-MM-DD-HH-MM-SS-RandomString
The time-based nature of the bucket structure and filenames makes it easy to extract any time period for analysis. Firehose treats everything it gets as text and will just append that text to a file with other messages. This can be a bit of a “gotcha” if each record needs to be on its own line. In the Lambda, it was simple enough to add a new line character at the end of each message as it is sent to Firehose.
With that, we have essentially achieved our initial goal—warehousing Slack messages. Messages are consumed via an elastic HTTP endpoint, processed via an elastic Lambda, sent to a fully managed Firehose stream, and warehoused for later processing in a predictable S3 bucket and object structure.
This post has focused on what we put in place to consume and warehouse Slack messages in real time. In the next post, we will turn our attention to what we are building to process the messages and get some insight—spoiler alert: we’re using Apache Spark6.